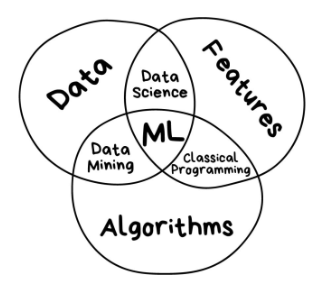
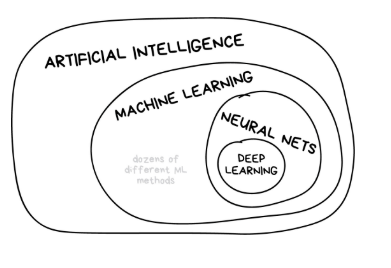
机器学习是人工智能更广泛领域的一个分支,它利用统计模型进行预测。它通常被描述为预测建模或预测分析的一种形式,传统上被定义为计算机在没有明确编程的情况下学习的能力。
在基本技术术语中,机器学习使用的算法将经验或历史数据纳入,分析并根据该分析生成输出。在某些方法中,算法首先处理所谓的“训练数据”,然后学习,预测并找到随着时间的推移提高其性能的方法。
1、什么是人工智能?
在计算机科学领域,人工智能领域是由艾伦·图灵(Alan Turing)于1950年创立。随着计算机的发展,人工智能领域不断发展,政府和行业都投入了大量资金。虽然一路上存在重大障碍,该领域也经历了几次收缩和平静期。
上世纪80年代,IBM的国际象棋计算机深蓝击败了国际象棋特级大师加里·卡斯帕罗夫(Gary Kasparov),这是人工智能社区的一个里程碑。2016年,谷歌的AlphaGo击败了围棋大师Lee Se Dol,这是另一个重要的里程碑。
过去几十年来,人工智能的其他进步包括机器人技术的发展以及语音识别软件的发展,近年来这些软件得到了显着改善。
2、机器学习的类型
机器学习有三种主要方法:监督式、无监督式和强化式学习。还有包括半监督学习在内的混合方法,可以根据研究人员寻求解决的问题进行定制。
每种方法都有特定的优缺点,某些技术比其他方法更适合特定类型的问题。
1.1有监督学习
经典机器学习通常分为两类:有监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)。
在“有监督学习”中,有一个“监督者”或者“老师”提供给机器所有的答案来辅助学习,比如图片中是猫还是狗。“老师”已经完成数据集的划分——标注“猫”或“狗”,机器就使用这些示例数据来学习,逐个学习区分猫或狗。
无监督学习就意味着机器在一堆动物图片中独自完成区分谁是谁的任务。数据没有事先标注,也没有“老师”,机器要自行找出所有可能的模式。
很明显,有“老师”在场时,机器学的更快,因此现实生活中有监督学习更常用到。有监督学习分为两类:
-
分类(classification),预测一个对象所属的类别;
-
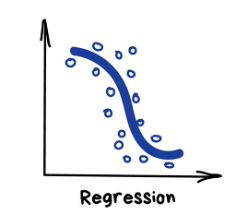
回归(regression),预测数轴上的一个特定点;
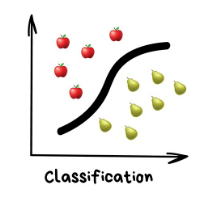
分类(Classification)
“基于事先知道的一种属性来对物体划分类别,比如根据颜色来对袜子归类,根据语言对文档分类,根据风格来划分音乐。”
分类算法常用于:
-
过滤垃圾邮件;
-
语言检测;
-
查找相似文档;
-
情感分析
-
识别手写字母或数字
-
欺诈侦测
常用的算法:
-
朴素贝叶斯(Naive Bayes)
-
决策树(Decision Tree)
-
Logistic回归(Logistic Regression)
-
K近邻(K-Nearest Neighbours)
-
支持向量机(Support Vector Machine)
机器学习主要解决“分类”问题。这时候数据就需要事先标注好,这样机器才能基于这些标签来学会归类。
回归(Regression)
“画一条线穿过这些点,嗯~这就是机器学习”
回归算法目前用于:
-
股票价格预测
-
供应和销售量分析
-
医学诊断
-
计算时间序列相关性
常见的回归算法有:
-
线性回归(Linear Regression)
-
多项式回归(PolynomialRegression)
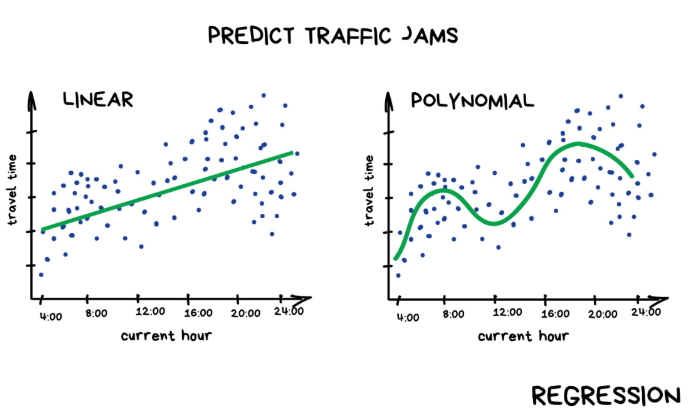
“回归”算法本质上也是“分类”算法,只不过预测的是不是类别而是一个数值。比如根据行驶里程来预测车的价格,估算一天中不同时间的交通量,以及预测随着公司发展供应量的变化幅度等。处理和时间相关的任务时,回归算法可谓不二之选。
回归算法备受金融或者分析行业从业人员青睐。它甚至成了Excel的内置功能,整个过程十分顺畅——机器只是简单地尝试画出一条代表平均相关的线。
不过,不同于一个拿着笔和白板的人,机器是通过计算每个点与线的平均间隔这样的数学精确度来完成的这件事。
如果画出来的是直线,那就是“线性回归”,如果线是弯曲的,则是“多项式回归”。它们是回归的两种主要类型。
1.2无监督学习
在无监督学习中,学习算法没有给出这种类型的指导,而是发现输入中的模式或结构。
两种主要类型的无监督学习是:1)聚类,涉及发现数据集中具有相似特征的组,2)降维,尽可能保存相关的结构的同时降低数据的复杂度。
无监督学习方法还包括数据和投影的可视化,这减少了数据的维度,这是一种简化的形式。
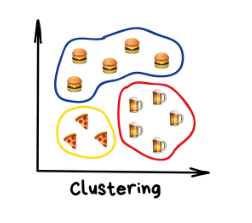
聚类(Clustering)
“机器会选择最好的方式,基于一些未知的特征将事物区分开来。”
聚类算法目前用于:
-
市场细分(顾客类型,忠诚度)
-
合并地图上邻近的点
-
图像压缩
-
分析和标注新的数据
-
检测异常行为
常见算法:
举个例子,在线地图上的标记。当你寻找周围的素食餐厅时,聚类引擎将它们分组后用带数字的气泡展示出来。不这么做的话,浏览器会卡住——因为它试图将这个时尚都市里所有的300家素食餐厅绘制到地图上。
Apple Photos和Google Photos用的是更复杂的聚类方式。通过搜索照片中的人脸来创建你朋友们的相册。应用程序并不知道你有多少朋友以及他们的长相,但是仍可以从中找到共有的面部特征。这是很典型的聚类。
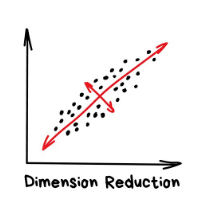
降维(Dimensionality Reduction)
“将特定的特征组装成更高级的特征”
“降维”算法目前用于:
-
推荐系统
-
漂亮的可视化
-
主题建模和查找相似文档
-
假图识别
-
风险管理
常用的“降维”算法:
-
主成分分析(Principal Component Analysis,PCA)
-
奇异值分解(Singular Value Decomposition,SVD)
-
潜在狄里克雷特分配(Latent Dirichlet allocation,LDA)
-
潜在语义分析(Latent Semantic Analysis,LSA,pLSA,GLSA),
-
t-SNE(用于可视化)
早期,“硬核”的数据科学家会使用这些方法,他们决心在一大堆数字中发现“有趣的东西”。Excel图表不起作用时,他们迫使机器来做模式查找的工作。于是他们发明了降维或者特征学习的方法。
1.3强化学习
在强化学习中,计算机和算法将在动态环境中遇到问题,当它努力执行给定的目标时,它将收到反馈(奖励),这将加强其学习和目标寻求的努力。阿尔法Go的例子是强化学习的一个例子;强化学习算法包括Q学习、时差学习和深度强化学习。
4、机器学习的应用实例
在金融市场中,机器学习用于自动化、投资组合优化、风险管理,并为投资者提供金融咨询服务。
对于算法交易形式的自动化,人工交易者将建立数学模型,分析金融新闻和交易活动,以识别市场趋势,包括交易量、波动性和可能的异常。这些模型将根据给定的指令集执行交易,一旦系统建立并运行,就可以在没有直接人工参与的情况下进行活动。
对于投资组合优化,机器学习技术可以帮助评估大量数据,确定模式,并为给定问题找到平衡风险和回报的解决方案。ML还可以帮助检测投资信号和时间序列预测。
图片
对于风险管理,机器学习可以帮助信用决策,也可以检测可疑交易或行为,包括KYC合规努力和防止欺诈。
对于金融咨询服务,机器学习支持了某些类型的散户投资者向机器人顾问的转变,帮助他们实现投资和储蓄目标。
对于金融咨询服务,机器学习支持了某些类型的散户投资者向机器人顾问的转变,帮助他们实现投资和储蓄目标。